Measuring Adaptation
| Distance Traveled | Controller Entropy |
 |
 |
| direct measure of behavior |
measure of structure |
| from unpublished
work with Dr. J. P. Crutchfield at the Santa Fe Institute |
|
circle experiment video
corner experiment video
next
The
graphs show the combined results of the three experiment series in two
different ways.
Looking at the Learned machine's results one can see that it starts out going about the same speed as the Random one but then inflects to the speed of the Designed machine. At the inflection point is where the learned evaluations take over from the random explorations. After that point the robot's speed is nearly the same as the Designed machine so we can infer that the learning algorithm is working fairly well. In the individual experiments the inflection point occurs at various times, the data displayed is an average over all the learning experiment runs.
The word Entropy is also a confusing term because it is used in the context of thermodynamics to mean energy loss. However the mathematics for calculating each is identical in form, and Johnny von Neumann (again...) suggested that Claude Shannon use entropy to describe his Information Theory. It turns out that one can be stated in terms of the other in many cases, so it wasn't such a bad idea.
Distance Traveled
On the left is the total distance traveled over time for each series. This is a pretty direct measurement of the the instincts given to the robots as evaluation criteria. As can be seen, the Designed machine travels the furthest from the start and the Random machine does the worst. The slope of the lines is the average speed of the robot, so we also see that the Designed machine goes fastest and the Random one slowest.Looking at the Learned machine's results one can see that it starts out going about the same speed as the Random one but then inflects to the speed of the Designed machine. At the inflection point is where the learned evaluations take over from the random explorations. After that point the robot's speed is nearly the same as the Designed machine so we can infer that the learning algorithm is working fairly well. In the individual experiments the inflection point occurs at various times, the data displayed is an average over all the learning experiment runs.
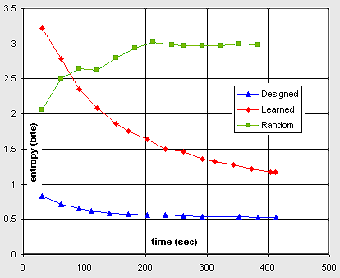
Controller Entropy
On the right is a plot of the Entropy of the controlling state machine over time for each experiment series. In this context Entropy is a big word for how random something is, where lower values are less random. One can see that after some time, the randomness of each controller parallels the measurements made using the Total Distance. Where the Random machine was slow, it's entropy is high and it is disordered; and, where the Designed machine was fast, its entropy is low and it is very ordered. The Learned machine shows a transition from high to low entropy, from disorder to order. Interestingly, this measure has nothing to do with the learning evaluation criteria and is thus more general as it indicates the amount structure in the controller itself.(Way Short) Discourse on Information Theory
Information is an unfortunate name for this because it gets confused with Meaning. In this context Information can be thought of as Surprise, i.e., how Surprised are you to get a new bit of information. If you had no way to know what the new event would be you are very surprised, and vice versa. In this sense then, random sequences are more surprising and thus contain more Information than predictable sequences. The measure of Information is Entropy, so a high Entropy means a lot of surprising Information.The word Entropy is also a confusing term because it is used in the context of thermodynamics to mean energy loss. However the mathematics for calculating each is identical in form, and Johnny von Neumann (again...) suggested that Claude Shannon use entropy to describe his Information Theory. It turns out that one can be stated in terms of the other in many cases, so it wasn't such a bad idea.